PANews 5月15日消息,据OpenAI官方公告,为提高模型安全透明度,OpenAI宣布上线“安全评估中心”(Safety Evaluations Hub),用于持续发布旗下模型在有害内容、越狱攻击、幻觉生成、指令优先级等方面的安全表现结果。相较于系统卡片只在模型发布时披露一次性数据,该中心将随模型更新周期性更新,支持不同模型间横向比较,旨在提升社区对AI安全性的理解与监管透明度。目前,GPT-4.5与GPT-4o在越狱攻击抵抗与事实准确性方面表现最为出色。
 利好
利好
 利空
利空



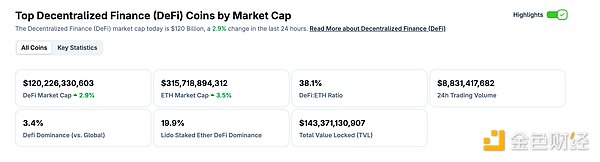







 Binance
Binance Bybit
Bybit Coinbase Exchange
Coinbase Exchange OKX
OKX Upbit
Upbit Kraken
Kraken Bitget
Bitget Raydium
Raydium Bitfinex
Bitfinex Uniswap v2
Uniswap v2 Bitcoin
Bitcoin Ethereum
Ethereum Tether USDt
Tether USDt XRP
XRP BNB
BNB Solana
Solana Dogecoin
Dogecoin USDC
USDC Cardano
Cardano TRON
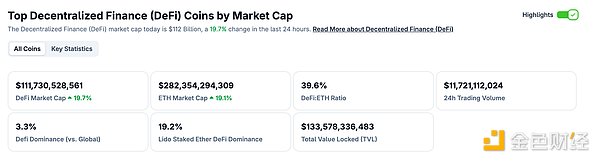
TRON
 行情
行情 
 平台
平台 
 首页
首页 
 观点
观点 
 快讯
快讯