高性能大模型在训练的过程中通常需要数千个GPU,耗费数月甚至更长时间才能完成一次训练。这种巨大的资源投入使得模型的每一层都必须高效训练,才能确保算力资源最大化利用。
但大连理工、西湖大学、牛津大学等研究人员对DeepSeek、Qwen、Llama和Mistral研究发现,这些模型的深层在训练过程中表现并不好,甚至可以被完全剪枝而不会影响模型性能。
例如,研究人员对DeepSeek-7B模型进行了逐层剪枝,以评估每一层对模型整体性能的贡献。结果显示,移除模型的深层对性能的影响微乎其微,而移除浅层性能会明显下降。这表明DeepSeek模型的深层在训练过程中未能有效学习到有用的特征,而浅层则承担了大部分的特征提取任务。
这种现象称为“深度诅咒”(Curse of Depth),同时研究人员也提出了一种有效的解决方法——LayerNorm Scaling(层归一化缩放)。

深度诅咒介绍
“深度诅咒”现象的根源在于Pre-LN的特性。Pre-LN是一种在Transformer架构模型中广泛使用的归一化技术,它在每一层的输入上进行归一化,而不是在输出上。这种归一化方式虽然能够稳定模型的训练过程,但也带来了一个严重的问题,随着模型深度的增加,Pre-LN的输出方差会呈指数级增长。
这种方差的爆炸性增长导致深层的Transformer块的导数接近于单位矩阵,使得这些层在训练过程中几乎不贡献任何有效的信息。换句话说,深层在训练过程中变成了单位映射,无法学习到有用的特征。
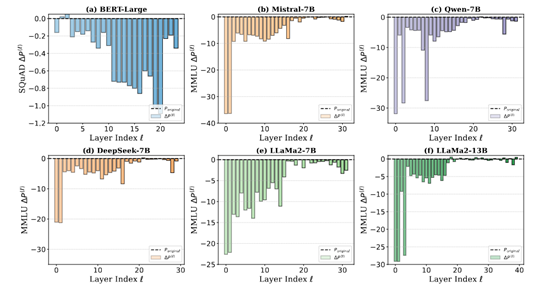
“深度诅咒”的存在对大语言模型的训练和优化带来了严重的挑战。首先,深层的训练不足导致了资源的浪费。在训练大语言模型时,通常需要大量的计算资源和时间。由于深层未能有效学习到有用的特征,算力资源在很大程度上被浪费了。
深层的无效性限制了模型性能的进一步提升。尽管浅层能够承担大部分的特征提取任务,但深层的无效性使得模型无法充分利用其深度优势。
此外,“深度诅咒”还对模型的可扩展性带来了难题。随着模型规模的增加,深层的无效性愈发突出,这使得模型的训练和优化变得更加困难。例如,在训练超大型模型时,深层的训练不足可能导致模型的收敛速度变慢,甚至无法收敛。
解决方法——LayerNorm Scaling
LayerNorm Scaling 的核心思想是对Pre-LN输出方差的精准控制。在一个多层的 Transformer 模型中,每一层的层归一化输出都会被乘以一个特定的缩放因子。这个缩放因子与当前层的深度密切相关,是层深度平方根的倒数。
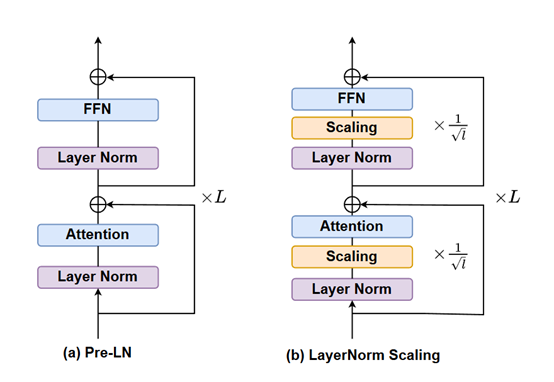
为大家举个简单易懂的例子,大模型就像一座高楼,每一层都是其中的一层楼,而 LayerNorm Scaling 就是给每一层楼的 “能量输出” 进行了精细调节。

对于较低的楼层(浅层),缩放因子相对较大,这意味着它们的输出被调整的幅度较小,能够保持相对较强的 “能量”;对于较高的楼层(深层),缩放因子较小,这样就有效地降低了深层输出的“能量强度”,避免了方差的过度积累。
通过这种方式,整个模型的输出方差得到了有效控制,不会再出现深层方差爆炸的情况。(整个计算过程比较复杂,有兴趣的小伙伴可以直接看论文)
从模型训练的视角来看,在传统的 Pre-LN 模型训练中,由于深层方差的不断增大,梯度在反向传播过程中会受到很大干扰。深层的梯度信息变得不稳定,这就像在传递接力棒时,接力棒在后面几棒的传递过程中总是掉落,导致信息传递不畅。
使得深层在训练时难以学习到有效的特征,模型的整体训练效果大打折扣。而 LayerNorm Scaling通过控制方差,稳定了梯度流。
在反向传播过程中,梯度能够更加顺畅地从模型的输出层传递到输入层,每一层都能接收到准确而稳定的梯度信号,从而能够更有效地进行参数更新和学习。
实验结果
为了验证LayerNorm Scaling的有效性,研究人员在不同规模的模型上进行了广泛的实验。实验涵盖了从1.3亿参数到10亿参数的模型。
实验结果显示,LayerNorm Scaling在预训练阶段显著提升了模型性能,与传统的Pre-LN相比,降低了困惑度,并减少了训练所需的token数量。
例如,在LLaMA-130M模型上,LayerNorm Scaling将困惑度从26.73降低到25.76,而在10亿参数的LLaMA-1B模型上,困惑度从17.02降低到15.71。这些结果表明,LayerNorm Scaling不仅能够有效控制深层的方差增长,还能够显著提升模型的训练效率和性能。
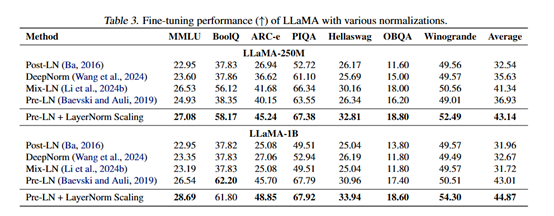
研究人员对LayerNorm Scaling在监督微调阶段的表现进行了评估。实验结果显示,LayerNorm Scaling在多个下游任务上均优于其他归一化技术。
例如,在LLaMA-250M模型上,LayerNorm Scaling在ARC-e任务上的性能提升了3.56%,在所有任务上的平均性能提升了1.80%。这表明,LayerNorm Scaling不仅在预训练阶段表现出色,在微调阶段也能够显著提升模型的性能。
此外,研究人员将DeepSeek-7B模型的归一化方法从传统的Pre-LN替换为LayerNorm Scaling。在整个训练过程中,深层块的学习能力得到了显著提升,能够积极地参与到模型的学习过程中,为模型的性能提升贡献力量。困惑度下降的幅度更为明显,下降速度也更稳定。




 行情
行情 
 平台
平台 
 首页
首页 
 观点
观点 
 快讯
快讯